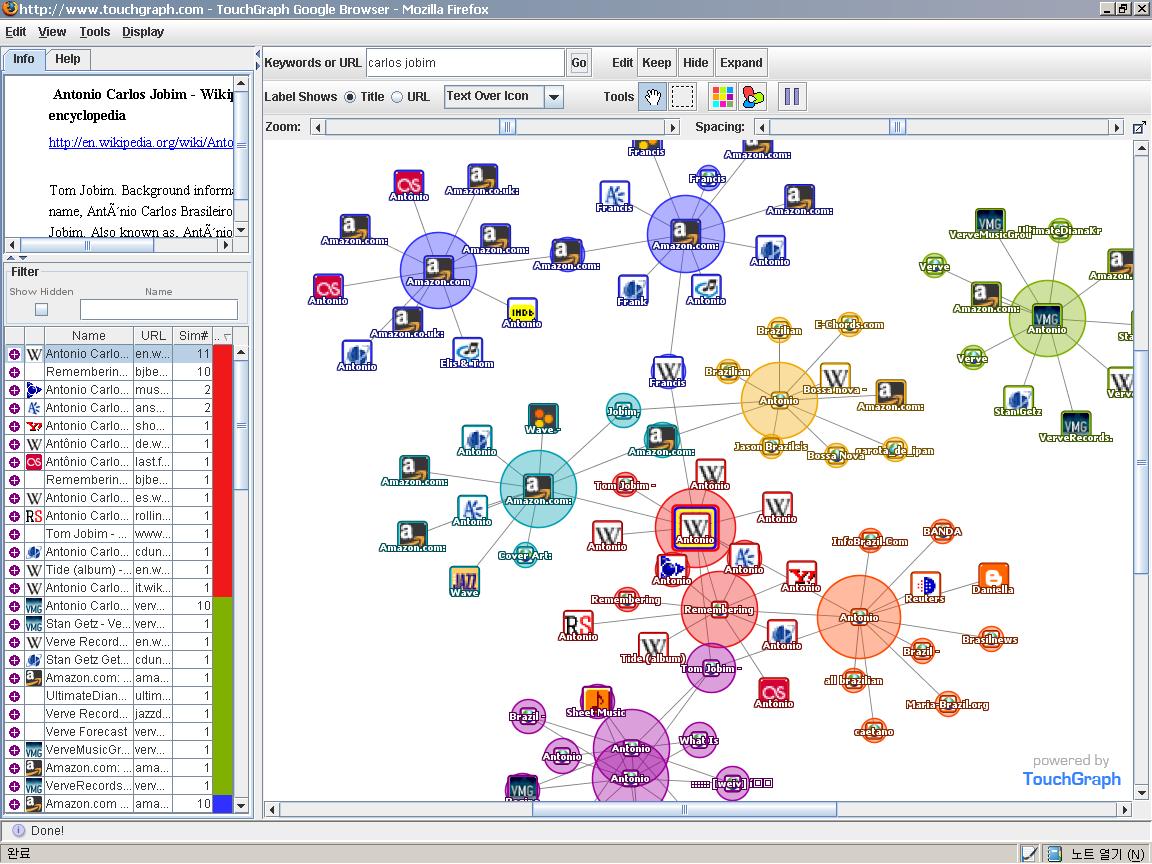
2007년 6월 7일 하버드 대학 졸업식 연설문입니다.
당연한 것일수도 있겠지만 참 빌게이츠스럽다(?)는 느낌이네요.
복잡성의 제거와 접목시켜서 불평등에 대한 이야기를하는군요. 그럴듯합니다.
Remarks of Bill Gates
Harvard Commencement
President Bok, former President Rudenstine, incoming President
Faust, members of the Harvard Corporation and the Board of Overseers,
members of the faculty, parents, and especially, the graduates:
I’ve been waiting more than 30 years to say this: “Dad, I always told you I’d come back and get my degree.”
I want to thank Harvard for this timely honor. I’ll be changing my
job next year … and it will be nice to finally have a college degree on
my resume.
I applaud the graduates today for taking a much more direct route to
your degrees. For my part, I’m just happy that the Crimson has called
me “Harvard’s most successful dropout.” I guess that makes me
valedictorian of my own special class … I did the best of everyone who
failed.
But I also want to be recognized as the guy who got Steve Ballmer to
drop out of business school. I’m a bad influence. That’s why I was
invited to speak at your graduation. If I had spoken at your
orientation, fewer of you might be here today.
Harvard was just a phenomenal experience for me. Academic life was
fascinating. I used to sit in on lots of classes I hadn’t even signed
up for. And dorm life was terrific. I lived up at Radcliffe, in Currier
House. There were always lots of people in my dorm room late at night
discussing things, because everyone knew I didn’t worry about getting
up in the morning. That’s how I came to be the leader of the
anti-social group. We clung to each other as a way of validating our
rejection of all those social people.
Radcliffe was a great place to live. There were more women up there,
and most of the guys were science-math types. That combination offered
me the best odds, if you know what I mean. This is where I learned the
sad lesson that improving your odds doesn’t guarantee success.
One of my biggest memories of Harvard came in January 1975, when I
made a call from Currier House to a company in Albuquerque that had
begun making the world’s first personal computers. I offered to sell
them software.
I worried that they would realize I was just a student in a dorm and
hang up on me. Instead they said: “We’re not quite ready, come see us
in a month,” which was a good thing, because we hadn’t written the
software yet. From that moment, I worked day and night on this little
extra credit project that marked the end of my college education and
the beginning of a remarkable journey with Microsoft.
What I remember above all about Harvard was being in the midst of so
much energy and intelligence. It could be exhilarating, intimidating,
sometimes even discouraging, but always challenging. It was an amazing
privilege – and though I left early, I was transformed by my years at
Harvard, the friendships I made, and the ideas I worked on.
But taking a serious look back … I do have one big regret.
I left Harvard with no real awareness of the awful inequities in the
world – the appalling disparities of health, and wealth, and
opportunity that condemn millions of people to lives of despair.
I learned a lot here at Harvard about new ideas in economics and
politics. I got great exposure to the advances being made in the
sciences.
But humanity’s greatest advances are not in its discoveries – but in
how those discoveries are applied to reduce inequity. Whether through
democracy, strong public education, quality health care, or broad
economic opportunity – reducing inequity is the highest human
achievement.
I left campus knowing little about the millions of young people
cheated out of educational opportunities here in this country. And I
knew nothing about the millions of people living in unspeakable poverty
and disease in developing countries.
It took me decades to find out.
You graduates came to Harvard at a different time. You know more
about the world’s inequities than the classes that came before. In your
years here, I hope you’ve had a chance to think about how – in this age
of accelerating technology – we can finally take on these inequities,
and we can solve them.
Imagine, just for the sake of discussion, that you had a few hours a
week and a few dollars a month to donate to a cause – and you wanted to
spend that time and money where it would have the greatest impact in
saving and improving lives. Where would you spend it?
For Melinda and for me, the challenge is the same: how can we do the
most good for the greatest number with the resources we have.
During our discussions on this question, Melinda and I read an
article about the millions of children who were dying every year in
poor countries from diseases that we had long ago made harmless in this
country. Measles, malaria, pneumonia, hepatitis B, yellow fever. One
disease I had never even heard of, rotavirus, was killing half a
million kids each year – none of them in the United States.
We were shocked. We had just assumed that if millions of children
were dying and they could be saved, the world would make it a priority
to discover and deliver the medicines to save them. But it did not. For
under a dollar, there were interventions that could save lives that
just weren’t being delivered.
If you believe that every life has equal value, it’s revolting to
learn that some lives are seen as worth saving and others are not. We
said to ourselves: “This can’t be true. But if it is true, it deserves
to be the priority of our giving.”
So we began our work in the same way anyone here would begin it. We asked: “How could the world let these children die?”
The answer is simple, and harsh. The market did not reward saving
the lives of these children, and governments did not subsidize it. So
the children died because their mothers and their fathers had no power
in the market and no voice in the system.
But you and I have both.
We can make market forces work better for the poor if we can develop
a more creative capitalism – if we can stretch the reach of market
forces so that more people can make a profit, or at least make a
living, serving people who are suffering from the worst inequities. We
also can press governments around the world to spend taxpayer money in
ways that better reflect the values of the people who pay the taxes.
If we can find approaches that meet the needs of the poor in ways
that generate profits for business and votes for politicians, we will
have found a sustainable way to reduce inequity in the world. This task
is open-ended. It can never be finished. But a conscious effort to
answer this challenge will change the world.
I am optimistic that we can do this, but I talk to skeptics who
claim there is no hope. They say: “Inequity has been with us since the
beginning, and will be with us till the end – because people just …
don’t … care.” I completely disagree.
I believe we have more caring than we know what to do with.
All of us here in this Yard, at one time or another, have seen human
tragedies that broke our hearts, and yet we did nothing – not because
we didn’t care, but because we didn’t know what to do. If we had known
how to help, we would have acted.
The barrier to change is not too little caring; it is too much complexity.
To turn caring into action, we need to see a problem, see a
solution, and see the impact. But complexity blocks all three steps.
Even with the advent of the Internet and 24-hour news, it is still a
complex enterprise to get people to truly see the problems. When an
airplane crashes, officials immediately call a press conference. They
promise to investigate, determine the cause, and prevent similar
crashes in the future.
But if the officials were brutally honest, they would say: “Of all
the people in the world who died today from preventable causes, one
half of one percent of them were on this plane. We’re determined to do
everything possible to solve the problem that took the lives of the one
half of one percent.”
The bigger problem is not the plane crash, but the millions of preventable deaths.
We don’t read much about these deaths. The media covers what’s new –
and millions of people dying is nothing new. So it stays in the
background, where it’s easier to ignore. But even when we do see it or
read about it, it’s difficult to keep our eyes on the problem. It’s
hard to look at suffering if the situation is so complex that we don’t
know how to help. And so we look away.
If we can really see a problem, which is the first step, we come to
the second step: cutting through the complexity to find a solution.
Finding solutions is essential if we want to make the most of our
caring. If we have clear and proven answers anytime an organization or
individual asks “How can I help?,” then we can get action – and we can
make sure that none of the caring in the world is wasted. But
complexity makes it hard to mark a path of action for everyone who
cares — and that makes it hard for their caring to matter.
Cutting through complexity to find a solution runs through four
predictable stages: determine a goal, find the highest-leverage
approach, discover the ideal technology for that approach, and in the
meantime, make the smartest application of the technology that you
already have — whether it’s something sophisticated, like a drug, or
something simpler, like a bednet.
The AIDS epidemic offers an example. The broad goal, of course, is
to end the disease. The highest-leverage approach is prevention. The
ideal technology would be a vaccine that gives lifetime immunity with a
single dose. So governments, drug companies, and foundations fund
vaccine research. But their work is likely to take more than a decade,
so in the meantime, we have to work with what we have in hand – and the
best prevention approach we have now is getting people to avoid risky
behavior.
Pursuing that goal starts the four-step cycle again. This is the
pattern. The crucial thing is to never stop thinking and working – and
never do what we did with malaria and tuberculosis in the 20th century
– which is to surrender to complexity and quit.
The final step – after seeing the problem and finding an approach –
is to measure the impact of your work and share your successes and
failures so that others learn from your efforts.
You have to have the statistics, of course. You have to be able to
show that a program is vaccinating millions more children. You have to
be able to show a decline in the number of children dying from these
diseases. This is essential not just to improve the program, but also
to help draw more investment from business and government.
But if you want to inspire people to participate, you have to show
more than numbers; you have to convey the human impact of the work – so
people can feel what saving a life means to the families affected.
I remember going to Davos some years back and sitting on a global
health panel that was discussing ways to save millions of lives.
Millions! Think of the thrill of saving just one person’s life – then
multiply that by millions. … Yet this was the most boring panel I’ve
ever been on – ever. So boring even I couldn’t bear it.
What made that experience especially striking was that I had just
come from an event where we were introducing version 13 of some piece
of software, and we had people jumping and shouting with excitement. I
love getting people excited about software – but why can’t we generate
even more excitement for saving lives?
You can’t get people excited unless you can help them see and feel the impact. And how you do that – is a complex question.
Still, I’m optimistic. Yes, inequity has been with us forever, but
the new tools we have to cut through complexity have not been with us
forever. They are new – they can help us make the most of our caring –
and that’s why the future can be different from the past.
The defining and ongoing innovations of this age – biotechnology,
the computer, the Internet – give us a chance we’ve never had before to
end extreme poverty and end death from preventable disease.
Sixty years ago, George Marshall came to this commencement and
announced a plan to assist the nations of post-war Europe. He said: “I
think one difficulty is that the problem is one of such enormous
complexity that the very mass of facts presented to the public by press
and radio make it exceedingly difficult for the man in the street to
reach a clear appraisement of the situation. It is virtually impossible
at this distance to grasp at all the real significance of the
situation.”
Thirty years after Marshall made his address, as my class graduated
without me, technology was emerging that would make the world smaller,
more open, more visible, less distant.
The emergence of low-cost personal computers gave rise to a powerful
network that has transformed opportunities for learning and
communicating.
The magical thing about this network is not just that it collapses
distance and makes everyone your neighbor. It also dramatically
increases the number of brilliant minds we can have working together on
the same problem – and that scales up the rate of innovation to a
staggering degree.
At the same time, for every person in the world who has access to
this technology, five people don’t. That means many creative minds are
left out of this discussion -- smart people with practical intelligence
and relevant experience who don’t have the technology to hone their
talents or contribute their ideas to the world.
We need as many people as possible to have access to this
technology, because these advances are triggering a revolution in what
human beings can do for one another. They are making it possible not
just for national governments, but for universities, corporations,
smaller organizations, and even individuals to see problems, see
approaches, and measure the impact of their efforts to address the
hunger, poverty, and desperation George Marshall spoke of 60 years ago.
Members of the Harvard Family: Here in the Yard is one of the great collections of intellectual talent in the world.
What for?
There is no question that the faculty, the alumni, the students, and
the benefactors of Harvard have used their power to improve the lives
of people here and around the world. But can we do more? Can Harvard
dedicate its intellect to improving the lives of people who will never
even hear its name?
Let me make a request of the deans and the professors – the
intellectual leaders here at Harvard: As you hire new faculty, award
tenure, review curriculum, and determine degree requirements, please
ask yourselves:
Should our best minds be dedicated to solving our biggest problems?
Should Harvard encourage its faculty to take on the world’s worst
inequities? Should Harvard students learn about the depth of global
poverty … the prevalence of world hunger … the scarcity of clean water
…the girls kept out of school … the children who die from diseases we
can cure?
Should the world’s most privileged people learn about the lives of the world’s least privileged?
These are not rhetorical questions – you will answer with your policies.
My mother, who was filled with pride the day I was admitted here –
never stopped pressing me to do more for others. A few days before my
wedding, she hosted a bridal event, at which she read aloud a letter
about marriage that she had written to Melinda. My mother was very ill
with cancer at the time, but she saw one more opportunity to deliver
her message, and at the close of the letter she said: “From those to
whom much is given, much is expected.”
When you consider what those of us here in this Yard have been given
– in talent, privilege, and opportunity – there is almost no limit to
what the world has a right to expect from us.
In line with the promise of this age, I want to exhort each of the
graduates here to take on an issue – a complex problem, a deep
inequity, and become a specialist on it. If you make it the focus of
your career, that would be phenomenal. But you don’t have to do that to
make an impact. For a few hours every week, you can use the growing
power of the Internet to get informed, find others with the same
interests, see the barriers, and find ways to cut through them.
Don’t let complexity stop you. Be activists. Take on the big inequities. It will be one of the great experiences of your lives.
You graduates are coming of age in an amazing time. As you leave
Harvard, you have technology that members of my class never had. You
have awareness of global inequity, which we did not have. And with that
awareness, you likely also have an informed conscience that will
torment you if you abandon these people whose lives you could change
with very little effort. You have more than we had; you must start
sooner, and carry on longer.
Knowing what you know, how could you not?
And I hope you will come back here to Harvard 30 years from now and
reflect on what you have done with your talent and your energy. I hope
you will judge yourselves not on your professional accomplishments
alone, but also on how well you have addressed the world’s deepest
inequities … on how well you treated people a world away who have
nothing in common with you but their humanity.
Good luck.
원문 http://www.commencement.harvard.edu/

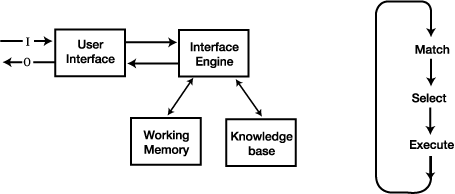

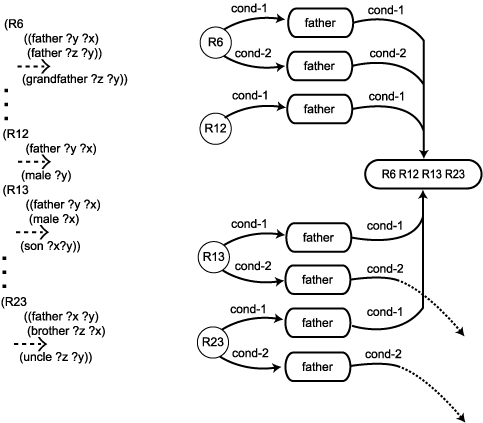
 SAN은 다양한 업무 프로세스로 분산되어 있는 저장장치를 통합 운영하여 업무의 효율성 증대, 인프라에대한 중복투자 방지 및
이기종간 데이터 공유를 목적으로 만들어진 서버와 저장장치간의 네트워크를 의미한다. 개별적으로 연결되어 있는 저장 시스템을 화이버
채널을 이용하여 별도의 전용 네트워크에 연결하여 집중 적으로 관리함으로써 데이터의 고속전송, 고 가용성, 확장성 및 공유 기능을
제공하 기 위한 시스템이다. [그림 4-9-2]는 SAN의 구조를 보여 준다.
SAN은 다양한 업무 프로세스로 분산되어 있는 저장장치를 통합 운영하여 업무의 효율성 증대, 인프라에대한 중복투자 방지 및
이기종간 데이터 공유를 목적으로 만들어진 서버와 저장장치간의 네트워크를 의미한다. 개별적으로 연결되어 있는 저장 시스템을 화이버
채널을 이용하여 별도의 전용 네트워크에 연결하여 집중 적으로 관리함으로써 데이터의 고속전송, 고 가용성, 확장성 및 공유 기능을
제공하 기 위한 시스템이다. [그림 4-9-2]는 SAN의 구조를 보여 준다. ![[그림 4-9-3]](http://www.dbguide.net/images/know/repo/g4-9-3.gif)



