예전에 패턴인식책에서 봤던 이 그림. 제대로 알아보자
http://slideplayer.com/slide/8218292/
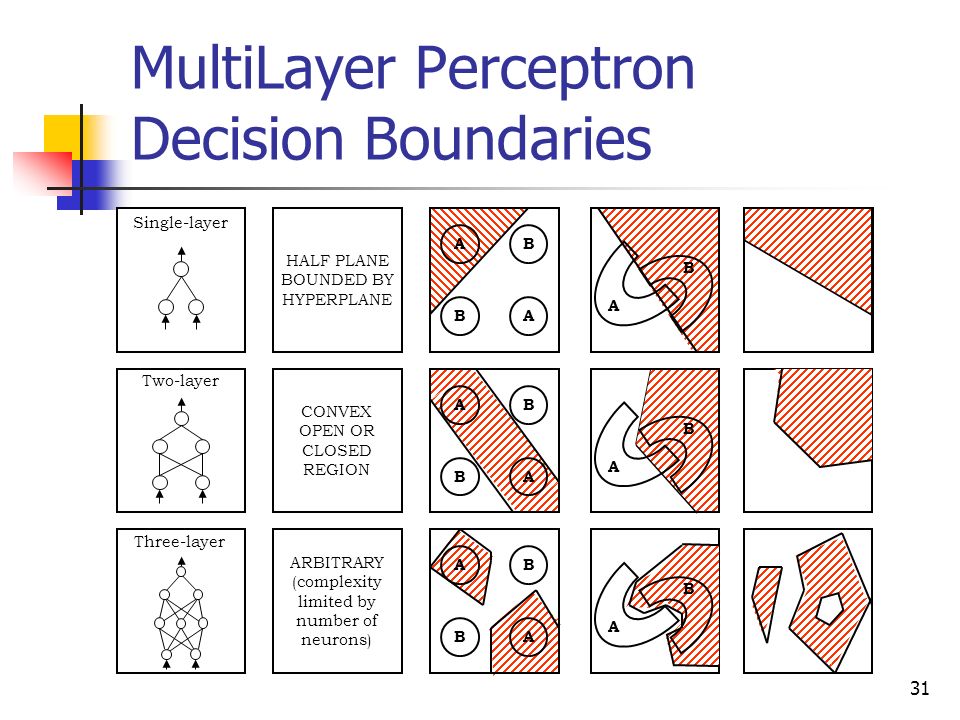
* Each neuron in the first hidden layer forms a hyperplane in the input pattern space.
* A neuron in the second hidden layer can form a hyper-region from
the outputs of the first layer neurons by performing an AND
operation on the hyperplanes. These neurons can thus approximate
the boundaries between pattern classes.
* The output layer neurons can then combine disjoint pattern classes
into decision regions made by the neurons in the second hidden
layer by performing logical OR operations.
(https://books.google.co.kr/books?isbn=0070482926)
아래 그림도 참고

http://t-robotics.blogspot.kr/2015/05/deep-learning.html#.WQZapNLyjAM
http://www.iro.umontreal.ca/~vincentp/
추가로,
No more than three layers in
binary threshold feedforward networks are required to form arbitrarily
complex decision regions.
Proof: By Construction
* Consider the n–dimensional case: X ∈ R n
.
* Partition the desired decision regions
into small hypercubes.
* Each hypercube requires 2n neurons in the
first layer
(one for each side of the hypercube).
* One neuron in the second layer takes the
logical AND of the
outputs from the first layer neurons.
Outputs of second
layer neurons will be high only for points
within the hypercube.
* Hypercubes are assigned to the proper
decision regions by
connecting the outputs of second layer
neurons to third
layer neurons corresponding to the decision
region that the
hypercubes represent by taking the logical
OR of
appropriate second layer outputs.
(https://books.google.co.kr/books?isbn=0070482926)
그럼, 히든 레이어와 노드수는 어떻게 결정할까

http://images.slideplayer.com/32/9894611/slides/slide_63.jpg
=> details
OR






 invalid-file
invalid-file