Rete: A Fast Algorithm for the Many Pattern/Many Object Pattern Match Problem
software 2007. 8. 30. 18:52- Jboss Drools(룰엔진) 매뉴얼 중에서 Rete Algorithm
- AIstudy 에 있는 번역글
출처: http://www.aistudy.co.kr/expert/rete_patterson.htm
THE RETE MATCHING ALGOROTHM
인공지능 개론 : Dan W. Patterson 저서, 김영렬.김우성.김정규.박용법.정목동 옮김, 지성출판사, 1995 (원서 : Introduction to Artificial Intelligence and Expert Systems, 1990), Page 258~262
생성 시스템 (production system) 들은 15장에서 기술된다. 그 시스템들은 전문가 시스템의 일반적인 구조이다. 전형적인 시스템은 생성 혹은 규칙의 형태로 영역 (domain) 전문가의 지식을 나타내는 구조를 포함한 지식 베이스와 현재 문제의 파라메터를 갖는 작업 메모리 (working memory) 와 어떤 규칙이 현재 문제에 적절한가를 결정하는 추론엔진 (inference engine) 을 포함한다.
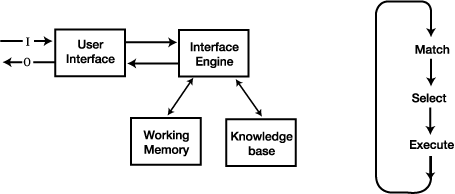
그림 1 생성시스템의 성분과 기본 사이클
생성 시스템의 기본적인 인터페이스 사이클은 그림 1에서 표시한 비교(match), 선택(select) 그리고 수행(excute)이다. 이러한 연산은 다음과 같이 수행된다.
비교 (Match) 사이클의 매치시간 동안 지식베이스내 규칙의 LHS(left hand side) 조건은 작업 메모리(working memory)를 계속 결합시키는 것을 만족하는 LHS 조건을 갖는 규칙이 무엇인지를 결정하기 위해 작업 메모리의 내용과 비교된다. 매치된 것으로 판명된 규칙들은 충돌집합(conflict set) 에 넣는다.
선택 (Select) 충돌 집합 (conflict set) 에서 규칙중의 하나가 선택되어 실행된다. 이러한 선택 정책은 최신 사용법, 특정한 규칙, 그 외의 기준에 의해 결정된다.
수행 (Execute) 충돌 집합에서 선택된 규칙은 그 기능 또는 규칙의 결말 부분 즉, 규칙의 RHS (Right Hand Side) 를 수행함으로써 작업 메모리 (working memory) 에서의 조항을 제거하거나 교체하는 것 또는 단순 정지 원인 및 입출력 연산, 덧셈과 같은 것들을 포함한다.
이상의 순환은 더 첨가될 규칙이 없거나 종결 조건에 도달될 때까지 되풀이된다. 전형적인 지식 베이스는 수백 또는 수천가지 이상의 규칙을 포함하는데 각 규칙은 몇가지(아마도 10여가지 이상의) 규칙들을 포함한다. 작업 메모리 역시 전형적으로 수백 가지 이상의 조항들을 포함한다. 결과적으로 작업메모리 (working memory) 에 대한 모든 규칙과 LHS 조건들을 소모적으로 매칭하는 데 수만번의 비교가 필요하다. 이러한 주장에 대한 설명은 서문에 잘 나타나 있는데 이러한 시스템은 계산 시간의 90% 정도가 매칭연산과 관련되어질 수 있다. 그러므로 각 사이클마다 매칭연산이 수 천번 수행되어지는 것을 제거할 수 있다. 이에 효과적인 매치 알고리즘을 개발하게 되었는데 이를 RETE라고 부른다. (Forgy, 1982)
RETE는 초기에 프로그래밍 언어의 OPS 계열의 일부분으로 개발되었다.(Brownston, et al 1985) 이러한 알고리즘에는 연속적인 사이클에서 비교가 반복되는 것을 피할 방법을 포함한 몇 가지 새로운 특성을 나타낸다.
RETE의 주요 시간 절약 특성은 다음과 같다.
대부분의 전문가 시스템에서 작업 메모리(working memory)의 내용은 사이클과 사이클 사이에서는 거의 변화가 없다. 데이타에는 임시 중복(temporal redundancy)이라고 알려진 지속성이 존재한다. 이것은 매 사이클마다 소모적 매칭을 불 필요하게 만든다. 대신, 매칭 정보를 저장함으로써 작업 메모리에의 변화를 사이클마다 비교하는 것만이 필요하게 된다.
게다가 RETE 에서는 작업 메모리의 대한 변화가 직접 충돌 집합으로 전송변환(mapping)되는 것을 막는다. (그림 2) 그 후 충돌 집합(conflict set)으로부터 한 규칙을 선택 실행할 때 그것은 집합에서 제거되고 남아있는 엔트리들은 다음 사이클을 위해서 저장된다. 즉, 작업 메모리에 대한 규칙들이 반복적으로 비교되는 것을 피하게 된다. 더 나아가 그들의 LHS에 나타나는 조건 조항(term)을 가지는 규칙을 색인화하여(indexing) 작업 메모리 교체에 매치되는 단지 그러한 규칙들 만 조사할 필요가 있다. 이것은 각 사이클에 요구되는 비교의 횟수를 상당히 감소 시킨다.

그림 2 작업 메모리에 대한 변화가 충돌집합으로 사상(mapping)
지식베이스의 대부분의 규칙들은 그것의 LHS 에서 발생하는 것과 같은 조건들을 가질 것이다. 이는 불 필요한 매칭이 발생할 수 있는 또 다른 방법이 되고 있다. 그러한 규칙들을 묶음으로서(grouping), 또한 동일 조건들을 공통항으로 연결하여 피할 수 있게 된다. 이는 모든 적용 가능한 규칙들에 대해 한번의 테스트를 실행함으로써 가능하게 될 것이다. 연결화(linking) 절차는 다음과 같다.
규칙이 처음으로 지식 베이스에 적재될 때 이것은 규칙 컴파일러에 의해 검사되고 처리된다. 컴파일러는 LHS조건을 체크하고 규칙 이름과 LHS 조건 조항사이의 결합을 형성한다. 또한 컴파일러는 LHS에서 공통 조건을 가지는 모든 규칙과 연결되는 네트워크 구조를 구축한다. 이 네트워크는 새로운 작업 메모리 조항에 일치되는 바인딩(binding)에 만족되는 규칙 조건을 찾아내서 실행시간 동안 검사하고 위치화(locate)시키는 데 사용된다. 그림 3은 공통 LHS 조항을 공유하는 규칙들이 어떻게 그룹화되고 (grouping) 공통조건 조항으로 색인화(indexing)될 수 있는 지를 설명해 주고 있다.
LISP를 사용하여 결합시키고 색인(indexing)화를 형성하는 한 방법은 특성 LISP를 사용하여 결합시키고 색인(indexing)화를 형성하는 한 방법은 특성리스트 (property list)로 가능하다. 예를 들면,
(putprop 'R6 'father 'cond-1)
(putprop 'R6 'father 'cond-2)
(putprop 'R12 'father 'cond-1)
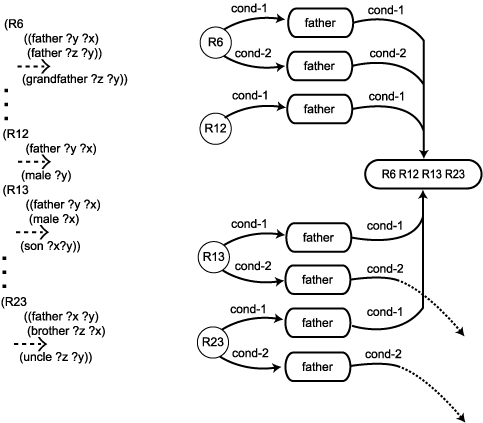
그림 3 전형적인 규칙과 컴파일된 네트워크 일부
규칙들과 LHS 조건 사이의 연결(link)을 만들어 주고, 다음과 같은 문은
(putprop 'father (cons R6 (get 'father 'cond-1) 'cond-1))
동일한 LHS 위치에 조항(term)을 포함하는 모든 규칙들에 구체화된 LHS 조항을 연결해 준다. 절(clause)의 첨가와 같이 작업 메모리의 교체가 일어날 때(father bill joe) LHS 조건으로서 father를 포함하는 모든 규칙은 쉽게 확인되고(identify) 검색될(retrieved) 수 있다.
RETE에서의 검색(retrieved)과 규칙 조건의 연속적인 검사는 토큰(token)을 만드는 것으로 시작되는데 이러한 토큰(token)은 규칙 컴파일러에 의해 구축된 네트워크를 통과하게 된다.
네트워크는 적절한 검사 경로를 제공하는데 이 검사는 동일한 바인딩(binding)을 이끌어 내고 LHS 규칙을 완전히 만족시킨다. 매치 비교기(matcher)는 새로운 매치나, 더 이상 작업 메모리 요소에 매치되지 않는 규칙을 찾아내는 네트워크를 돌아다닌다. 매치 비교기(matcher)로부터 출력되는 것은 쌍(pair)으로 된 요소로 구성된 자료구조이다. 즉, 규칙 이름과 (R6 ( father bob sam ) (father mike bob))과 같은 LHS에 매치된 작업 메모리 요소의 리스트(list)이다.
독자는 다음 장에 제시될 색인화(indexing) 방법과 위에서 기술한 색인화(indexing) 방법이 유사하다는 것을 알 수 있다. 그 외 다른 시간 절약 기술도 RETE에서 적용된다. 그러나 위에서 쓰인 방법이 가장 중요한 방법이라고 할 수 있다. 실제로 이것은 수백 또는 수만 가지에 이르는 조건을 완전히 매치하는 것을 줄이는 방법을 제공한다.



